How TabPFN Uses In-Context Learning to Achieve Higher Accuracy on Tabular Data Compared to Random Forest and CatBoost

Tabular data—structured information stored in rows and columns—is at the heart of many real-world machine learning problems, from health care records to financial transactions. Over the years, models based on decision trees, such as Random Forest, XGBoostagain CatBoosthas become the default option for these jobs. Their strengths lie in handling mixed data types, capturing complex feature interactions, and delivering robust performance without heavy pre-processing. While deep learning has revolutionized areas such as computer vision and natural language processing, it has historically struggled to outperform these tree-based methods on tabular datasets.
That long-standing practice is now being questioned. A new way, TabPFNpresents a different approach to table problems—one that completely avoids special training of the data set. Instead of learning from scratch each time, it relies on a pre-trained model to make predictions directly, effectively turning a large part of the learning process into decision time. In this article, we take a closer look at this idea and test it by comparing TabPFN with established tree-based models such as Random Forest and CatBoost on a sample dataset, evaluating their performance in terms of accuracy, training time, and inference speed.

TabPFN is a tabular base model it is designed to handle structured data in a completely different way than traditional machine learning. Instead of training a new model for every dataset, TabPFN i pre-trained for millions of table operations produced in causal processes. This allows it to learn a general strategy for solving supervised learning problems. When you give it your dataset, it doesn’t go through iterative training like tree-based models—instead, it makes predictions directly using what it’s already learned. Actually, it works kind of learning within content in tabular data, similar to how large language models work in text.
The latest version, TabPFN-2.5, greatly expands this concept by supporting large and complex datasets, while also improving performance. It has been shown outperforms tree-based tuned models such as XGBoost and CatBoost on standard benchmarks and even compare to robust integration programs like AutoGluon. At the same time, it reduces the need for hyperparameter tuning and manual effort. To enable real-world deployments, TabPFN also introduces the distillation methodwhere its predictions can be converted into smaller models such as neural networks or tree ensembles—maintaining more accuracy while allowing for much faster predictions.

Setting dependencies
pip install tabpfn-client scikit-learn catboostimport time
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Models
from sklearn.ensemble import RandomForestClassifier
from catboost import CatBoostClassifier
from tabpfn_client import TabPFNClassifierTo use the model, you need a TabPFN API key. You can find the same from
import os
from getpass import getpass
os.environ['TABPFN_TOKEN'] = getpass('Enter TABPFN Token: ')Creates a dataset
In our study, we generate a synthetic binary classification dataset using make_classification from scikit-learn. The data set consists of 5,000 samples and 20 features, of which 10 are informative (actually contribute to the target prediction) and 5 are irrelevant (found in information). This setup helps simulate a real table situation where not all features are equally useful, and some introduce noise or correlation.
We then split the data into training (80%) and testing (20%) sets to test the performance of the model on unobserved data. Using a synthetic dataset allows us to have full control over data characteristics while ensuring fair and reproducible comparisons between TabPFN and traditional tree-based models.
X, y = make_classification(
n_samples=5000,
n_features=20,
n_informative=10,
n_redundant=5,
random_state=42
)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)Random Forest Testing
We start with the Random Forest classifier as a base, using 200 trees. Random Forest is a robust clustering method that builds multiple decision trees and aggregates their predictions, making it a robust and reliable choice of tabular data without requiring hard tuning.
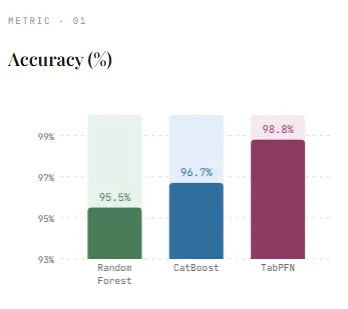
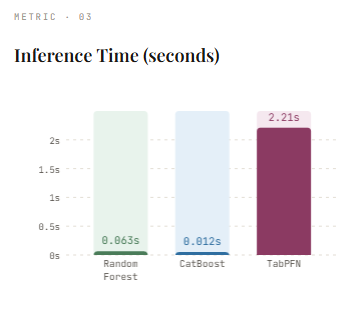
After training on the dataset, the model achieves an accuracy of 95.5%which is robust performance given the synthetic nature of the data. However, this comes with training time 9.56 seconds, showing the cost of building hundreds of trees. On the plus side, the guesswork is relatively quick 0.0627 seconds, since the predictions include only transferring data to already created trees. This result serves as a solid basis for comparison with more advanced methods such as CatBoost and TabPFN.
rf = RandomForestClassifier(n_estimators=200)
start = time.time()
rf.fit(X_train, y_train)
rf_train_time = time.time() - start
start = time.time()
rf_preds = rf.predict(X_test)
rf_infer_time = time.time() - start
rf_acc = accuracy_score(y_test, rf_preds)
print(f"RandomForest → Acc: {rf_acc:.4f}, Train: {rf_train_time:.2f}s, Infer: {rf_infer_time:.4f}s")Testing CatBoost
Next, we train the CatBoost class, a gradient boosting model designed specifically for tabular data. Build trees in sequence, where each new tree corrects previous mistakes. Compared to Random Forest, CatBoost is generally more accurate due to this optimization method and its ability to model complex patterns more effectively.
On our dataset, CatBoost achieves an accuracy of 96.7%which surpasses Random Forest and shows its power as a modern tree-based approach. It also trains a little faster, it takes 8.15 seconds, despite using 500 repetitions. One of its biggest advantages is the speed of thinking—prediction is just that much faster 0.0119 seconds, making it well suited for production situations where low latency is important. This makes CatBoost a solid benchmark before comparing to newer methods like TabPFN.
cat = CatBoostClassifier(
iterations=500,
depth=6,
learning_rate=0.1,
verbose=0
)
start = time.time()
cat.fit(X_train, y_train)
cat_train_time = time.time() - start
start = time.time()
cat_preds = cat.predict(X_test)
cat_infer_time = time.time() - start
cat_acc = accuracy_score(y_test, cat_preds)
print(f"CatBoost → Acc: {cat_acc:.4f}, Train: {cat_train_time:.2f}s, Infer: {cat_infer_time:.4f}s")Testing TabPFN
Finally, we examine TabPFN, which takes a very different approach compared to traditional models. Instead of learning from scratch on the dataset, it uses a pre-trained model and simply imposes conditions on the training data at decision time. The .fit() step mainly involves loading pretrained weights, which is why it’s so fast.
In our dataset, TabPFN achieves the highest accuracy of 98.8%more efficient than Random Forest and CatBoost. It’s the right time 0.47 seconds, much faster than tree-based models since no real training is performed. However, this change comes with a trade-off—inference takes 2.21 seconds, much slower than CatBoost and Random Forest. This is because TabPFN processes both training and test data together during prediction, effectively performing a “learning” step during prediction.
Overall, TabPFN shows a strong advantage in accuracy and speed of setup, while highlighting the different computational trade-offs compared to conventional tabular models.
tabpfn = TabPFNClassifier()
start = time.time()
tabpfn.fit(X_train, y_train) # loads pretrained model
tabpfn_train_time = time.time() - start
start = time.time()
tabpfn_preds = tabpfn.predict(X_test)
tabpfn_infer_time = time.time() - start
tabpfn_acc = accuracy_score(y_test, tabpfn_preds)
print(f"TabPFN → Acc: {tabpfn_acc:.4f}, Fit: {tabpfn_train_time:.2f}s, Infer: {tabpfn_infer_time:.4f}s")In all our tests, TabPFN delivers the strongest performance, achieving the highest accuracy (98.8%) while requiring no training time (0.47s) compared to Random Forest (9.56s) and CatBoost (8.15s). This highlights its key advantage: eliminating dataset-specific training and large-scale parameter tuning while still performing very well with well-established tree-based methods. However, this benefit comes with a trade-off—The inference latency is very high (2.21s)as the model processes both training and test data together during prediction. In contrast, CatBoost and Random Forest offer faster inference, making them more suitable for real-time applications.
From a practical point of view, TabPFN is very effective small to medium table jobsrapid testing, and situations where reducing development time is important. In manufacturing environments, especially those that require low-latency prediction or handling very large data sets, new developments such as TabPFN distillation engine to help close this gap by transforming the model into neural networks or clusters of trees, retaining much of its accuracy while greatly improving the speed of reasoning. Additionally, the support for scaling to millions of rows makes it more effective in business use cases. Overall, TabPFN represents a change in tabular machine learning—trading the traditional training effort for a more flexible, index-driven approach.


Check it out Full Codes with Notebook here. Also, feel free to follow us Twitter and don’t forget to join our 130k+ ML SubReddit and Subscribe to Our newspaper. Wait! are you on telegram? now you can join us on telegram too.
Need to work with us on developing your GitHub Repo OR Hug Face Page OR Product Release OR Webinar etc.? Connect with us

I am a Civil Engineering Graduate (2022) from Jamia Millia Islamia, New Delhi, and I am very interested in Data Science, especially Neural Networks and its application in various fields.



