The Lakehouse Pipeline: Integrating Data and Analytics Engineering into Contemporary Enterprise Architectures

Most data platforms fail because of a lack of tools. Failures are due to excessive attempts by the system to solve the same problem independently, leading to conflicting data, time lags, and loss of trust.
A set of statistical systems and layers are stored in the machine learning environment. However, the division continues. The teams continue to work with various proofs of the same data. Pipes extend into areas that do not meet specifications. Reports are late, or worse, conflicting.
The problem is usually not the tools. It is how systems are configured and interact.
When ingest, storage, analytics, and machine learning are used in separate layers, redundant data is difficult to deal with. Governance is undermined, and teams spend time making sure checks are done better than using data.
The lakehouse pipeline addresses this at the architectural level. As data-driven analytics and data engineering are brought to a single control point, it transforms the flow of data within the enterprise. It leads to the creation of scalable and parallel architectures, which can support analytics and AI, realizing the fundamental principles of modern data.
Why Traditional Data Architecture Continues with Fragmented Data
Most of the data centers of the enterprise have not started to be classified. That’s how they became over time.
Data lakes have evolved to handle scale. Databases are handled by structured statistics. Different pipelines tried to bridge the gap. Over time, each layer evolved independently.
Over time, that separation created a set of common problems:
- Multiple copies of the same data across systems
- Delay between import and analysis
- Inconsistent data management policies
Teams often try to fix this with multiple pipelines or manual work, often adding complexity instead of solving the problem.
The root of the problem is the separation of properties. The scope of the analysis work depends on the selected datasets. Engineering workflows depend on crude pipelines. Separating the two is a source of tension.
The result of this trend has been the emergence of the data lakehouse, which combines storage and analysis into a single architectural design to reduce duplication and improve consistency across systems.
Defining the Lakehouse Pipeline as an Integrated Data Platform
A lakehouse pipeline is a combination of the flexibility and functionality of data lakes and the architecture and functionality of data warehouses. It acts as a unified platform where:
- Raw and structured data coexist
- Engineering and SQL workflows share the same datasets
- Governance works continuously throughout the life cycle
This model eliminates the need for parallel pipelines and reduces the risk of conflicting metrics across teams.
Change in architecture is more important than technology. From pipeline orchestration to platform architecture is changing the way organizations think about data engineering management practices and analytics, especially when common storage, metadata layers, and similar access patterns exist among workloads.
Understanding the Lakehouse Pipeline Lifecycle
A lakehouse pipe does not follow a simple linear flow. It behaves more like an integrated system where the layers interact continuously. Some pipes don’t fail outright. They just slow down over time.
If you look at the end, you can see how these layers connect and work together as a single system.
Import and Storage
Data comes in through applications, streaming platforms, and external sources. Batch and real-time import work within the same structure.
Storage is storage in an open format where structured and unstructured data can coexist. Trust is provided by processes such as ACID functions that allow for compatibility with workloads.
Transformation and metadata
Raw data is used only after filtering. Transformation layers standardize, validate, and enrich data sets.
Metadata plays an important role here. Enables:
- Data acquisition and cataloging
- Schema tracing
- Appearance of lineage
Without robust metadata services, fragmentation quickly returns, even in medium-sized systems.
Asking and using
SQL analytics, machine learning pipelines, and data science workflows are also supported on the same platform. This integration allows a single pipeline to power dashboards, reporting, and AI scenarios without duplicating data for different teams.
Organizing Data Using Medallion Architecture
As pipelines grow, design becomes important. The medallion architecture organizes data into layers that improve quality and usability over time.
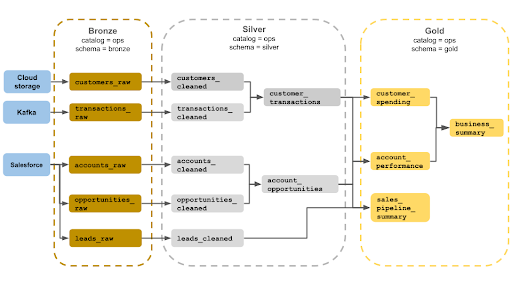
- I copper layer it captures the raw data with little change
- I silver layer calibrates and cleans data sets
- I layer of gold delivers curated, business-friendly data
This layered approach helps teams work on consistent definitions and reduces duplication throughout the pipeline.
The structure has become a standard reference point for planning data engineering and statistical workflows, especially with layered development patterns that separate raw inputs from selected business datasets.
The Technical Basics That Make Lakehouse Plumbing Work
A lakehouse pipe depends on several important skills:
- Open table formats like Delta Lake
- Use of schema to maintain data quality
- Support for schema evolution as a system scale
- Integrated computing engines for mixed workloads
These elements allow developer pipelines and analysis queries to run on the same platform.
The model works well under controlled conditions. As concurrency increases, it becomes more complex. Transaction consistency with large amounts of data is a daunting task to handle. Its design must accommodate multiple workloads while ensuring that distributed tables are synchronized.
From Fragmentation to AI-Ready Data Platforms
Structural changes can feel invisible until they start to affect real results. When used correctly, the lakehouse pipeline leads to clear, measurable improvements:
- Fewer duplicate data copies
- Faster access to trusted information by reducing data latency
- The same metrics for all groups
- Strong data management with clear ownership, traceability, and organization
Organizations that align their data architecture with business use cases are more likely to see measurable impact from analytics, in some cases up to 3x more likely to achieve value than disparate environments.
Traditional vs Lakehouse Architecture
| Power | Traditional | The Lakehouse |
| Storage | Different systems | Integrated Forum |
| Data duplication | At the top | It has been taken down |
| Dominance | It is separated | It is centralized |
| Mathematical speed | A little bit | Immediately |
| AI readiness | It has a limit | It’s built in |
Adoption trends reinforce this direction. About 70% of organizations expect the workload to shift to lakehouse structures, while more than half report costs reduced by more than 50% after consolidating their data centers.
Challenges and Challenges of Lakehouse Property Acquisitions
The model comes with some disadvantages. Organizations often meet:
- Complex migration from legacy systems
- Skills gaps
- The challenges of tuning the performance of a mixed workload
- Management is dangerous if ownership is not clear
Architecture can be used effectively when there is transparency in governance and stability, but uncertainty when there is disagreement between groups and ownership.
Isolation is not complete by being placed in only one place. It shifts to accountability for consistency and communication.
Lakehouse as an Effective Business Data Model
The lakehouse pipe is a storage method and a working model.
It brings data engineering and analytics processes together and enables machine learning without creating additional pipelines. It will reduce group conflict and reduce the distance between input and understanding.
Leading a company with this model is a shift to integrated data segments, instead of separate pipelines. The result is a scalable, AI-ready data platform that enables continuous decision-making.
From Separation to Support
Breakups rarely fix themselves. It requires careful structural adjustment.
Another way forward is the adoption of the lakehouse pipeline, which will combine data engineering and analytics into a single system. Benefits are also emerging as teams stop reconciling data and start using it.
The second thing is to check your existing pipes and identify where the duplication and delays are occurring. Then start consolidating that workflow into one place so teams can work on the same database.
This strategy cannot guarantee that all of these can be processed simultaneously, but it creates a strong foundation for consistent and scalable data usage.
Author Bio

Manuj Arora is a senior solutions architect with over 20 years of experience in enterprise data systems and cloud architecture. He specializes in designing scalable, managed data platforms for modern analytics.
References:



